代码先锋网 代码片段及技术文章聚合
Caffe源码解读:lrn_layer层原理
LRN全称为Local Response Normalization,即局部响应归一化层,具体实现在CAFFE_ROOT/src/caffe/layers/lrn_layer.cpp和同一目录下lrn_layer.cu中。
该层需要参数有:
norm_region: 选择对相邻通道间归一化还是通道内空间区域归一化,默认为ACROSS_CHANNELS,即通道间归一化;
local_size:两种表示(1)通道间归一化时表示求和的通道数;(2)通道内归一化时表示求和区间的边长;默认值为5;
alpha:缩放因子(详细见后面),默认值为1;
beta:指数项(详细见后面), 默认值为5;
局部响应归一化层完成一种“临近抑制”操作,对局部输入区域进行归一化。
在通道间归一化模式中,局部区域范围在相邻通道间,但没有空间扩展(即尺寸为 local_size x 1 x 1);
在通道内归一化模式中,局部区域在空间上扩展,但只针对独立通道进行(即尺寸为 1 x local_size x local_size);
每个输入值都将除以
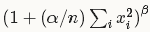
【卜居注:写作时的 Caffe 版本较旧,新版 Caffe 已经增加参数 k,变为 (k + (alpha / n) ……),感谢 @云峰 同学指出】
其中n为局部尺寸大小local_size, alpha和beta前面已经定义。
求和将在当前值处于中间位置的局部区域内进行(如果有必要则进行补零)。
不过根据实验,LRN在很多情况下作用不大。
以下是caffe中的源码:
//局部响应归一化层完成一种“临近抑制”操作,对局部输入区域进行归一化
//前向传播
template <typename Dtype>
void LRNLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
switch (this->layer_param_.lrn_param().norm_region()) {
//通道间归一化
case LRNParameter_NormRegion_ACROSS_CHANNELS:
CrossChannelForward_cpu(bottom, top);
break;
//通道内归一化
case LRNParameter_NormRegion_WITHIN_CHANNEL:
WithinChannelForward(bottom, top);
break;
default:
LOG(FATAL) << "Unknown normalization region.";
}
}
//通道间归一化前向传播
template <typename Dtype>
void LRNLayer<Dtype>::CrossChannelForward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
//所求的系数,最后该层每个元素都要乘相应位置的系数
Dtype* scale_data = scale_.mutable_cpu_data();
// start with the constant value
// 初始化值1.0
for (int i = 0; i < scale_.count(); ++i) {
scale_data[i] = k_;
}
//波段数由channels_扩展至 channels_ + size_ - 1,即前后各扩展size/2
Blob<Dtype> padded_square(1, channels_ + size_ - 1, height_, width_);
Dtype* padded_square_data = padded_square.mutable_cpu_data();
caffe_set(padded_square.count(), Dtype(0), padded_square_data);
//预先计算公式中的alpha/n, size_表示局部尺寸,此时为求和的通道数
Dtype alpha_over_size = alpha_ / size_;
// go through the images
for (int n = 0; n < num_; ++n) {
// compute the padded square
// bottom 所有元素进行平方,保存在padded_square_data中,从第pre_pad_个波段开始保存
// padded_square_data前后各补充了pre_pad_个波段,默认初始化为0
caffe_sqr(channels_ * height_ * width_,
bottom_data + bottom[0]->offset(n),
padded_square_data + padded_square.offset(0, pre_pad_));
// Create the first channel scale
// 计算第0个通道的系数,即将通道0到size-1的元素平方乘以预先算好的(alpha/n)进行累加
// 结果保存在scale_中
for (int c = 0; c < size_; ++c) {
caffe_axpy<Dtype>(height_ * width_, alpha_over_size,
padded_square_data + padded_square.offset(0, c),
scale_data + scale_.offset(n, 0));
}
// 计算其他通道的系数
// 每次向后移动一个单位,加头去尾,避免重复计算求和
for (int c = 1; c < channels_; ++c) {
// copy previous scale
caffe_copy<Dtype>(height_ * width_,
scale_data + scale_.offset(n, c - 1),
scale_data + scale_.offset(n, c));
// add head
caffe_axpy<Dtype>(height_ * width_, alpha_over_size,
padded_square_data + padded_square.offset(0, c + size_ - 1),
scale_data + scale_.offset(n, c));
// subtract tail
caffe_axpy<Dtype>(height_ * width_, -alpha_over_size,
padded_square_data + padded_square.offset(0, c - 1),
scale_data + scale_.offset(n, c));
}
}
// In the end, compute output
// 计算求指数,由于将除法转换为乘法,故指数变负
caffe_powx<Dtype>(scale_.count(), scale_data, -beta_, top_data);
// bottom .* scale_ -> top
caffe_mul<Dtype>(scale_.count(), top_data, bottom_data, top_data);
}
//通道内归一化前向传播
template <typename Dtype>
void LRNLayer<Dtype>::WithinChannelForward(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
// 将bottom[0]复制到split_top_vec_中的每一个blob
// split_top_vec_[0]是product_input_,split_top_vec_[1]是square_input_
split_layer_->Forward(bottom, split_top_vec_);
// 每个元素平方
// square_bottom_vec_其实是square_input_
square_layer_->Forward(square_bottom_vec_, square_top_vec_);
// 将每个元素周围元素相加
pool_layer_->Forward(square_top_vec_, pool_top_vec_);
// Compute y = (shift + scale * x)^-power
power_layer_->Forward(pool_top_vec_, power_top_vec_);
// top等于product_bottom_vec_中bottom[0]至bottom[n]的内积
// product_bottom_vec_[0]是product_input_,product_bottom_vec_[1]是power_top_vec_指针
product_layer_->Forward(product_bottom_vec_, top);
}
智能推荐
Caffe源码 - inner_product_layer 全连接层
Caffe - 全连接层 inner_product_layer 图像分类中,网络结构的最后一般有一个或多个全连接层. 全连接层的每个节点都与其上层的所有节点相连,以综合前面网络层提取的特征. 其全连接性,导致参数较多. 全连接层将卷积的 2D 特征图结果转化为 1D 向量. 如 MNIST: 最后两层为全连接层,在pooling 层后,转化为 1D 的 1*100 长度的向量. 全连接层的前向计...
caffe源码阅读之layer(2)——DataLayer层(2)
四、数据转换器 主要用于对原始数据预处理的方法,包括:随机切块、随机镜像、幅度缩放、去均值和灰度/色度变换等。数据转换器的类为 DataTransformer 成员变量 1、构造函数 2、数据转换 数据转换功能主要由Transform()函数实现,切块的大小、幅度缩放、随机镜像、去均值等功能,主要由以下5种函数实现函数重载。 Datum数据结构主要用于从LMDB/LEVELDB读取数据,或者写入数...
caffe源码阅读之layer(2)——DataLayer层
caffe数据读取层是layer的派生类,用于读取LMDB、LEVELDB,也可以直接读取图片,下面看看caffe怎么读取数据的,该代码的实现在 E:\Caffe\caffe-windows\src\caffe\layers中的base_data_layer.cpp和E:\Caffe\caffe-windows\include\caffe\layers中的base_dat...
【caffe】Layer解读之:Flatten
Layer type: Flatten 头文件位置:./include/caffe/layers/flatten_layer.hpp CPU 执行源文件位置: ./src/caffe/layers/flatten_layer.cpp Flatten层的功能:Flatten层是把一个输入的大小为n * c * h * w变成一个简单的向量,其大小为 n * (c*h*w)。可以用reshape代替~...
【caffe】Layer解读之:Reshape
2018年08月11日 17:36:14 yuanCruise 阅读数:793更多 所属专栏: Caffe源码学习 版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qiu931110/article/details/81588956 Layer type: Reshape 头文件位置:./in...
猜你喜欢
【caffe】Layer解读之:SoftmaxWithLoss
Layer type: SoftmaxWithLoss 头文件位置: ./include/caffe/layers/softmax_loss_layer.hpp CPU 执行源文件位置: ./src/caffe/layers/softmax_loss_layer.cpp CUDA GPU 执行源文件位置: ./src/caffe/layers/softmax_loss_layer.cu Softm...
【caffe】Layer解读之:Eltwise
Layer type: Eltwise 头文件位置:./include/caffe/layers/eltwise_layer.hpp CPU 执行源文件位置: ./src/caffe/layers/eltwise_layer.cpp CUDA GPU 执行源文件位置: ./src/caffe/layers/eltwise_layer.cu Eltwise层的功能:按元素操作层(Resnet 中的s...
【caffe】Layer解读之:Concat
Layer type: Concat 头文件位置: ./include/caffe/layers/concat_layer.hpp CPU 执行源文件位置:./src/caffe/layers/concat_layer.cpp CUDA GPU 执行源文件位置: ./src/caffe/layers/concat_layer.cu Concat层的功能:Concat层是一个实用程序层,它将多个输入...
【caffe】Layer解读之:Slience
Layer type: Silence 头文件位置:./include/caffe/layers/silence_layer.hpp CPU 执行源文件位置: ./src/caffe/layers/silence_layer.cpp CUDA GPU 执行源文件位置: ./src/caffe/layers/silence_layer.cu Slience层的功能:当用slice层把标签分割成多份,...
【caffe】Layer解读之:Flatten
Layer type: Flatten 头文件位置:./include/caffe/layers/flatten_layer.hpp CPU 执行源文件位置: ./src/caffe/layers/flatten_layer.cpp Flatten层的功能:Flatten层是把一个输入的大小为n * c * h * w变成一个简单的向量,其大小为 n * (c*h*w)。可以用reshape代替~...