代码先锋网 代码片段及技术文章聚合
pd.read_csv读取文件路径出现的问题
技术标签: 深度学习 pytorch python python pytorch 深度学习
写在前面
在用pd.read_csv读取数据集时,我有2个疑问?1是:写相对路径还是绝对路径。2是:相对路径,绝对路径怎么写。这篇文章就是解决以上两个问题。如果这个脚本只是在自己电脑上,都可以无所谓,但是如果别人也想用你的脚本,我认为相对路径还是比较好的,数据集和脚本一起拷贝给别人,如果环境没问题的话路径不用修改就可以直接运行,如果你用绝对路径的话,别人拿到之后还得自己修改路径。
出现的问题
报错,这个路径没找到文件,路径写错了。

解决问题
一般是数据集与你的脚本在一个文件夹下。 我用的是绝对路径
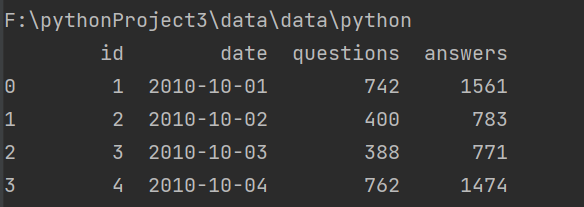
第1步打印脚本所在的路径
import os
os.getcwd()
print(os.getcwd())

第2步
加上你的数据集路径
train = pd.read_csv('F:\\pythonProject3\\data\\data\\train.csv')
下面是我的脚本和数据集的文件。
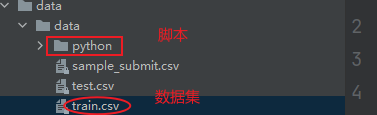
第3步测试一下
print(train)
用相对路径读取数据集
前提数据集与脚本不在同一个文件下,但同在上一级文件夹。就是下面这种情况。
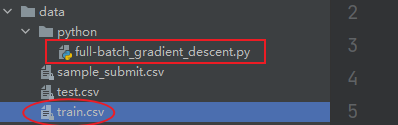
读取文件方式
train = pd.read_csv('..\\train.csv')
图中的“..”表示是当前所处的文件夹上一级文件夹的绝对路径。也就是我下图中data路径
F:\pythonProject3\data\data
实在不理解可以自己试试
import os
path1=os.path.abspath('.') #表示当前所处的文件夹的绝对路径
print("path1@@@@@",path1)
path2=os.path.abspath('..') ## 表示当前所处的文件夹上一级文件夹的绝对路径
print("path2@@@@@",path2)
完整的代码
import pandas as pd
import numpy as np
import os
os.getcwd()
# F:\\pythonProject3\\data\\data\\train.csv
# dataset_path = '..'
train = pd.read_csv('..\\train.csv')
path1=os.path.abspath('.')
print("path1@@@@@",path1)
path2=os.path.abspath('..')
print("path2@@@@@",path2)
print(train)
参考
智能推荐
pd.read_csv无法正常读取csv文件,显示UnicodeDecodeError
在mac的python3环境下,用pd.read_csv读取csv文件时,一直报错 在终端中 输入以下命令:file /Users/Downloads/A_Card/application.csv ,得到以下结果: /Users/Downloads/A_Card/application.csv: ASCII text, with very long lines, with C...
python用pd.read_csv()方法来读取csv文件
csv文件是一种用,和换行符区分数据记录和字段的一种文件结构,可以用excel表格编辑,也可以用记事本编辑,是一种类excel的数据存储文件,也可以看成是一种数据库。pandas提供了pd.read_csv()方法可以读取其中的数据并且转换成DataFrame数据帧。python的强大之处就在于他可以把不同的数据库类型,比如txt/csv/.xls/.sql转换成统一的DataFrame格式然后进...
pd.read_csv用法
pd.read_csv(filepath_or_buffer, sep=’, ‘, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=Non...
pd.read_csv()参数
...
pd.read_csv用法
重要参数: filepath_or_buffer : 路径 URL 可以是http, ftp, s3, 和 file. sep: 指定分割符,默认是’,’C引擎不能自动检测分隔符,但Python解析引擎可以 delimiter: 同sep delimiter_whitespace: True or False 默认False, 用空格作为分隔符等价于spe=’\...
猜你喜欢
pd.read_csv()函数
pd.read_csv()用于读取csv文件。CSV (Comma Separated Vaules) 格式是电子表格和数据库中最常见的输入、输出文件格式。...
04 ,df 创建 : 读 csv 文件,pd.read_csv
1 ,读 csv 文件 :pd.read_csv(“titanic_train.csv”) 读 csv 文件 : pd.read_csv(“titanic_train.csv”)...
pd.read_csv时出现unnamed列
pd.read_csv读入文件时出现unnamed列解决办法 出现unnamed列的原因 之所以会出现unnamed列,是因为我们把DataFrame写入到excel或者csv文件时,把索引也作为一列写入。 解决办法 在写入数据时参数index设置为False,即index=False 从csv或者excel加载数据时,使用index_col=0; 以上两种方法任选其一即可。 若以上两种方法都不能...
小内存服务器python pd.read_csv()下载文件out of memory的问题
最近在linux云服务器,2G RAM 上跑一些Python程序,需要下载csv.gz文件,但文件可能又几百M,很容易导致out of memory错误。 最终采用requests,分块下载,存入文件的防止,解决了问题。 需要在get函数中,将stream设置为True。...
pd.read_csv()忽略源文件索引
如下图,直接读取csv文件,原csv文件中索引列没有名字,读入python后自动加了名字叫做unnamed: 0 源文件: 读入python: 问题:如何不读入索引列,或者读入时直接命名 read_csv默认文件没有行列索引 关于列名 关于行索引...